|
|
The Stanford Natural Language Processing Group home · people · teaching · research · publications · software · events · local |
|
|
The Stanford Natural Language Processing Group home · people · teaching · research · publications · software · events · local |
![Printer Icon [www.famfamfam.com]](printer.png) Print-friendly version
Screen version
Version 0.4.0
Print-friendly version
Screen version
Version 0.4.0
The Stanford Topic Modeling Toolbox (TMT) brings topic modeling tools to social scientists and others who wish to perform analysis on datasets that have a substantial textual component. The toolbox features that ability to:

The Stanford Topic Modeling Toolbox was written at the Stanford NLP group by:
Daniel Ramage and Evan Rosen, first released in September 2009.
TMT was written during 2009-10 in what is now a very old version of Scala, using a linear algebra library that is also no longer developed or maintained. Some people still use this code and find it a friendly piece of software for LDA and Labeled LDA models, and more power to you. If you're just using the software bundle as is, it'll probably work fine. However, if you're trying to incorporate this code into a larger project, you'll have deep trouble due to its age. At this point we really can't offer any support or fix any problems. Sorry about that. If someone would like to take over the code and update it, let us know.
You might also look at other implementations of Labeled LDA. The software situation for Labeled LDA (as opposed to plain LDA) isn't great, but a few things you could look at are: Myle Ott's Java JGibbLaleledLDA, Shuyo's Python implementation, and Taske Hamano's implementation. Let us know if you know about others or these ones do or don't work. (Contact: java-nlp-support@lists.stanford.edu )

Download |
Programmers
See the API Reference. |
Upgrading from 0.2.x?The example scripts and data file have changed since the previous release. Make sure to update your scripts accordingly. (Don't forget to check the imports!) |
This section contains software installation instructions and the overviews the basic mechanics of running the toolbox.
More ...java -jar tmt-0.4.0.jarexample-0-test.scala
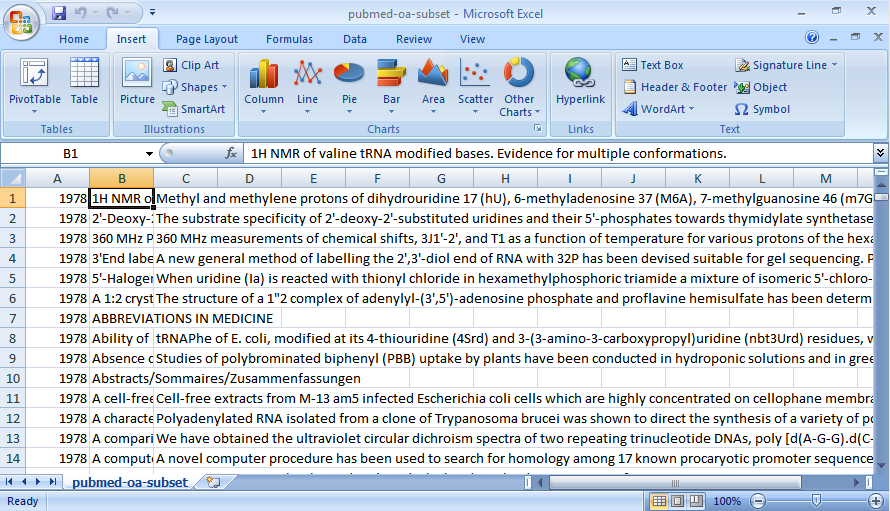
// TMT Example 0 - Basic data loading import scalanlp.io._; val pubmed = CSVFile("pubmed-oa-subset.csv"); println("Success: " + pubmed + " contains " + pubmed.data.size + " records");
This is a simple script that just loads the records contained in the sample data file pubmed-oa-subset, an subset of the Open Access database of publications in Pubmed.
Now run the toolbox as before and select "Open script ..." from the file menu. Navigate to example-0-test.scala and click open, then run.
Alternatively, you can run the script from the command line:
java -jar tmt-0.4.0.jar example-0-test.scala
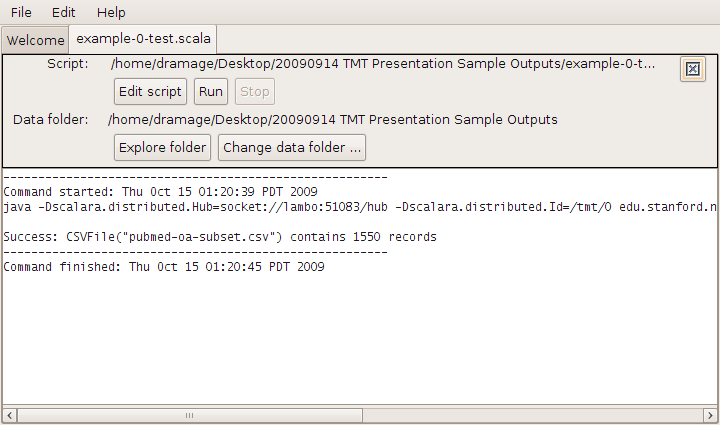
If all goes well you should see the following lines of output:
Success: CSVFile("pubmed-oa-subset.csv") contains 1550 records
You're all set to continue with the tutorial. For the rest of the tutorial, invoke the toolbox in the same way as we do above but with a different script name.
[close section]The first step in using the Topic Modeling Toolbox on a data file (CSV or TSV, e.g. as exported by Excel) is to tell the toolbox where to find the text in the file. This section describes how the toolbox converts a column of text from a file into a sequence of words.
The code for this example is in example-1-dataset.scala.
More ...The process of extracting and preparing text from a CSV file can be thought of as a pipeline, where a raw CSV file goes through a series of stages that ultimately result in something that can be used to train the topic model. Here is a sample pipeline for the pubmed-oa-subset.csv data file:
val source = CSVFile("pubmed-oa-subset.csv") ~> IDColumn(1);
val tokenizer = {
SimpleEnglishTokenizer() ~> // tokenize on space and punctuation
CaseFolder() ~> // lowercase everything
WordsAndNumbersOnlyFilter() ~> // ignore non-words and non-numbers
MinimumLengthFilter(3) // take terms with >=3 characters
}
val text = {
source ~> // read from the source file
Column(4) ~> // select column containing text
TokenizeWith(tokenizer) ~> // tokenize with tokenizer above
TermCounter() ~> // collect counts (needed below)
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
The input data file (in the source variable) is a pointer to the CSV file you downloaded earlier, which we will pass through a series of stages that each transform, filter, or otherwise interact with the data. In line one, we instruct TMT to use the value in column 1 as the record ID, a unique identifier for each record in the file. If your sheet's record IDs are in a different column, change the 1 value in line one above to the appropriate column. If your sheet does not have a record ID column, you can leave off the "~> IDColumn(1)" and TMT will use the line number in the file as the record id.
If the first row in your CSV file contains the column names, you can remove that row using the Drop stage:
val source = CSVFile("your-csv-file.csv") ~> IDColumn(yourIdColumn) ~> Drop(1);
The first step is to define a tokenizer that will convert the cells containing text in your dataset to terms that the topic model will analyze. The tokenizer, defined in lines 3 through 7, is specified as a series of transformations that convert a string to a sequence of strings.
First, we use the SimpleEnglishTokenizer() to remove punctuation from the ends of words and then split up the input text by whitespace characters (tabs, spaces, carriage returns, etc.). You could alternatively use the WhitespaceTokenizer() if your text fields have already been processed into cleaned tokens. Or you can specify a custom tokenizer based on a regular expression by using the RegexSplitTokenizer("your-regex-pattern").
The CaseFolder is then used to lower-case each word so that "The" and "tHE" and "THE" all look like "the". Case folding reduces the number of distinct word types seen by the model by turning all character to lowercase.
Next, words that are entirely punctuation and other non-word non-number characters are removed from the generated lists of tokenized documents by using the WordsAndNumbersOnlyFilter.
Finally, terms that are shorter than 3 characters are removed using the MinimumLengthFilter.
Optionally, tokens can be stemmed using a PorterStemmer() stage in the series of transformations just before the MinimumLengthFilter. Stemming is a common technique in information retrieval to collapse simple variations such as pluralization into a single common term ("books" and "book" both map to "book"). However, stemming doesn't always add value in a topic modeling context, because stemming sometimes combines terms that would best be considered distinct, and variations of the same word will usually end up in the same topic anyway.
If you want to remove standard english language stop words, you can use a StopWordFilter("en") as the last step the tokenizer.
After defining the tokenizer, we can use this tokenizer to extract text from the appropriate column(s) in the CSV file. If your text data is in a single column (here, the fourth column):
source ~> Column(4) ~> TokenizeWith(tokenizer)
The code above will load the text from column four in the CSV file.
If your text is in more than one column:
source ~> Columns(3,4) ~> Join(" ") ~> TokenizeWith(tokenizer)
The code above select columns two and three, and then concatenates their contents with a space character used as glue.
Topic models can be useful for extracting patterns in meaningful word use, but they are not good at determining which words are meaningful. It is often the case that the use of very common words like 'the' do not indicate the type of similarity between documents in which one is interested. To lead LDA towards extracting patterns among meaningful words, we implemented a collection of standard heuristics:
... ~> TermCounter ~> TermMinimumDocumentCountFilter(4) ~> TermDynamicStopListFilter(30) ~> ...
The code above removes terms appear in less than four documents (because very rare words tell us little about the similarity of documents), and 30 most common words in the corpus (because words that are ubiquitous also tell us little about the similarity of documents, they are removed and conventionally denoted "stop words"). These values might need to be updated if you are working with a much larger or much smaller corpus than a few thousand documents.
If you have an explicit list of stop words you would like removed from your corpus, you can add an extra stage to the processing: TermStopListFilter(List("positively","scrumptious")). Here, add as many terms as you like, in quotes, within the List. Remember that the TermStopListFilter is run after the text has already been tokenized, so the list you provide should match the output of your tokenizer - e.g. terms should already be lower-cased and stemmed if your tokenizer includes a CaseFolder and PorterStemmer.
The TermCounter stage must first compute some statistics needed by the next stages. These statistics are stored in the metadata associated with each parcel, which enables any downstream stage to access that information. This stage will also generate a cache file on disk in the same folder as the underlying CSVFile that saves the stored document statistics. The file name will start with the name of the underlying CSV file and include a signature of the pipeline "term-counts.cache".
DocumentMinimumLengthFilter(length) to remove all documents shorter than the specified length.
Run example 1 (example-1-dataset.scala). This program will first load the data pipeline and then print out information about the loaded text dataset, including a signature of the dataset and the list of 30 stop words found for this corpus. [Note that in PubMed, "gene" is filtered out because it is so common!]
[close section]Once you've prepared a dataset to learn against, you're all set to train a topic model. This example shows how to train an instance of Latent Dirichlet Allocation using the dataset you prepared above.
The code for this example is in example-2-lda-learn.scala
More ...
val source = CSVFile("pubmed-oa-subset.csv") ~> IDColumn(1);
val tokenizer = {
SimpleEnglishTokenizer() ~> // tokenize on space and punctuation
CaseFolder() ~> // lowercase everything
WordsAndNumbersOnlyFilter() ~> // ignore non-words and non-numbers
MinimumLengthFilter(3) // take terms with >=3 characters
}
val text = {
source ~> // read from the source file
Column(4) ~> // select column containing text
TokenizeWith(tokenizer) ~> // tokenize with tokenizer above
TermCounter() ~> // collect counts (needed below)
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
This code snippet is the same as in the previous tutorial. It extracts and prepares the text from the example dataset.
// turn the text into a dataset ready to be used with LDA val dataset = LDADataset(text); // define the model parameters val params = LDAModelParams(numTopics = 30, dataset = dataset);Here, you can specify any number of topics you'd like to learn. You can optionally specify alternative parameters for the Dirichlet term and topic smoothing used by the LDA model by providing extra arguments to the
LDAModelParams constructor on line 5: by default, line 5 is equivalent assumes termSmoothing=SymmetricDirichletParams(.1) and topicSmoothing=SymmetricDirichletParams(.1) have been provided as arguments.
As of version 0.3, the toolkit supports multiple forms of learning and inference on most topic models, including the default form that supports multi-threaded training and inference on modern multi-core machines. Specifically, the model can use a collapsed Gibbs sampler [T. L. Griffiths and M. Steyvers. 2004. Finding scientific topics. PNAS, 1:5228–35] or the collapsed variational Bayes approximation to the LDA objective [Asuncion, A., Welling, M., Smyth, P., & Teh, Y. W. (2009). On Smoothing and Inference for Topic Models. UAI 2009].
// Name of the output model folder to generate
val modelPath = file("lda-"+dataset.signature+"-"+params.signature);
// Trains the model: the model (and intermediate models) are written to the
// output folder. If a partially trained model with the same dataset and
// parameters exists in that folder, training will be resumed.
TrainCVB0LDA(params, dataset, output=modelPath, maxIterations=1000);
// To use the Gibbs sampler for inference, instead use
// TrainGibbsLDA(params, dataset, output=modelPath, maxIterations=1500);
The model will output status messages as it trains, and will write the generated model into a folder in the current directory named, in this case "lda-59ea15c7-30-75faccf7". It'll take a few minutes. Note that, by default, training using CVB0LDA will use as many processing cores as are available on the machine, and, because of its faster convergence rates, CVB0LDA needs to run for fewer iterations than GibbsLDA. However, GibbsLDA requires less memory during training.
The generated model output folder, in this case lda-59ea15c7-30-75faccf7, contains everything needed to analyze the learning process and to load the model back in from disk.
| description.txt | A description of the model saved in this folder. |
| document-topic-distributions.csv | A csv file containing the per-document topic distribution for each document in the dataset. |
| [Snapshot]: 00000 - 01000 | Snapshots of the model during training. |
| [Snapshot]/params.txt | Model parameters used during training. |
| [Snapshot]/tokenizer.txt | Tokenizer used to tokenize text for use with this model. |
| [Snapshot]/summary.txt | Human readable summary of the topic model, with top-20 terms per topic and how many words instances of each have occurred. |
| [Snapshot]/log-probability-estimate.txt | Estimate of the log probability of the dataset at this iteration. |
| [Snapshot]/term-index.txt | Mapping from terms in the corpus to ID numbers (by line offset). |
| [Snapshot]/topic-term-distributions.csv.gz | For each topic, the probability of each term in that topic. |
A simple way to see if the training procedure on the model has converged is to look at the values in the numbered folders of log-probability-estimate.txt. This file contains an informal estimate of the model's estimation of the probability of the data while training. The numbers tend to make a curve that tapers off but never stops changing completely. If the numbers don't look like they've stabilized, you might want to retrain using a higher number of iterations.
During training, the toolbox records the per-document topic distribution for each training document in a file called document-topic-distributions.csv in the generated model folder. After a model is trained, it can be used to analyze another (possibly larger) body of text, a process called inference. This tutorial shows how to perform inference on a new dataset using an existing topic model.
The code for this example is in example-3-lda-infer.scala
More ...
// the path of the model to load
val modelPath = file("lda-59ea15c7-30-75faccf7");
println("Loading "+modelPath);
val model = LoadCVB0LDA(modelPath);
// Or, for a Gibbs model, use:
// val model = LoadGibbsLDA(modelPath);
Here, we re-load the model trained in the previous example.
// A new dataset for inference. (Here we use the same dataset
// that we trained against, but this file could be something new.)
val source = CSVFile("pubmed-oa-subset.csv") ~> IDColumn(1);
val text = {
source ~> // read from the source file
Column(4) ~> // select column containing text
TokenizeWith(model.tokenizer.get) // tokenize with existing model's tokenizer
}
// Base name of output files to generate
val output = file(modelPath, source.meta[java.io.File].getName.replaceAll(".csv",""));
// turn the text into a dataset ready to be used with LDA
val dataset = LDADataset(text, termIndex = model.termIndex);
Here, we prepare the new dataset, tokenizing with the loaded model's original tokenizer. Note: in this particular example, we are actually using the same file as we trained against. In expected use, the referenced CSVFile would be to a different file on disk.
We also construct the base of the output path file name - the generated files, below, will go into the model folder with a name that starts with the name of the inference dataset.
println("Writing document distributions to "+output+"-document-topic-distributions.csv");
val perDocTopicDistributions = InferCVB0DocumentTopicDistributions(model, dataset);
CSVFile(output+"-document-topic-distributuions.csv").write(perDocTopicDistributions);
println("Writing topic usage to "+output+"-usage.csv");
val usage = QueryTopicUsage(model, dataset, perDocTopicDistributions);
CSVFile(output+"-usage.csv").write(usage);
Here, we infer the per-document topic distributions for each document in the inference dataset, writing these distributions to a new CSV file in the model folder. We also write a file containing how often each topic is used in the inference dataset.
println("Estimating per-doc per-word topic distributions");
val perDocWordTopicDistributions = EstimatePerWordTopicDistributions(
model, dataset, perDocTopicDistributions);
println("Writing top terms to "+output+"-top-terms.csv");
val topTerms = QueryTopTerms(model, dataset, perDocWordTopicDistributions, numTopTerms=50);
CSVFile(output+"-top-terms.csv").write(topTerms);
Because it differs from the dataset on which the model was trained, we expect that the inference dataset may make use of each learned topic in a way that is not exactly the same as how the topics were used during training. The toolbox can generate the top-k terms per topic as seen through the lens of the inference dataset. Here, we generate these top-k terms into the "-top-terms.csv" file. This file should be compared to the output in summary.txt or the output from running inference on the training dataset as a sanity check to ensure that the topics are used in a qualitatively similar way in the inference dataset as in the training dataset.
[close section]Documents are often associated with explicit metadata, such as the year a document was published, its source, authors, etc. In this tutorial, we show how TMT can be used to examine how a topic is used in each slice of the data, where a slice is the subset associated with one or more categorical variables.
The code for this example is in example-4-lda-slice.scala
More ...
// the path of the model to load
val modelPath = file("lda-59ea15c7-30-75faccf7");
println("Loading "+modelPath);
val model = LoadCVB0LDA(modelPath);
// Or, for a Gibbs model, use:
// val model = LoadGibbsLDA(modelPath);
As before, we re-load a model from disk.
// A dataset for inference; here we use the training dataset
val source = CSVFile("pubmed-oa-subset.csv") ~> IDColumn(1);
val text = {
source ~> // read from the source file
Column(4) ~> // select column containing text
TokenizeWith(model.tokenizer.get) // tokenize with existing model's tokenizer
}
// turn the text into a dataset ready to be used with LDA
val dataset = LDADataset(text, termIndex = model.termIndex);
Here, we re-load the same dataset used for training, but a different dataset could be used instead.
// define fields from the dataset we are going to slice against val slice = source ~> Column(2); // could be multiple columns with: source ~> Columns(2,7,8)In our example, the year each document was written is stored in column 2, which we will use as our categorical variable for slicing the dataset. If you want to slice by multiple categorical variables, you can use the
Columns stage.
println("Loading document distributions");
val perDocTopicDistributions = LoadLDADocumentTopicDistributions(
CSVFile(modelPath,"document-topic-distributions.csv"));
// This could be InferCVB0DocumentTopicDistributions(model, dataset)
// for a new inference dataset. Here we load the training output.
The code above loads the per-document topic distributions generated during training; if you use a different dataset for inference, you may need to replace LoadLDADocumentTopicDistributions with InferCVB0DocumentTopicDistributions or load from a different path.
println("Writing topic usage to "+output+"-sliced-usage.csv");
val usage = QueryTopicUsage(model, dataset, perDocTopicDistributions, grouping=slice);
CSVFile(output+"-sliced-usage.csv").write(usage);
println("Estimating per-doc per-word topic distributions");
val perDocWordTopicDistributions = EstimatePerWordTopicDistributions(
model, dataset, perDocTopicDistributions);
println("Writing top terms to "+output+"-sliced-top-terms.csv");
val topTerms = QueryTopTerms(model, dataset, perDocWordTopicDistributions, numTopTerms=50, grouping=slice);
CSVFile(output+"-sliced-top-terms.csv").write(usage);
Here, we generate the usage of each topic in the dataset by slice of the data. Like the
We also generate the top words associated with each topic within each group. The generated -sliced-top-terms.csv file can be used to analyze if topics are used consistently across sub-groups.
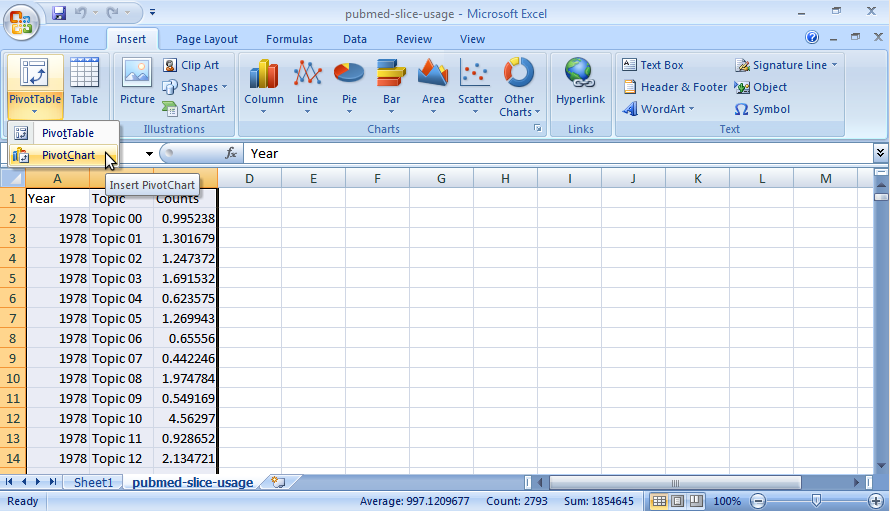
[close section]The CSV files generated in the previous tutorial can be directly imported into Excel to provide an advanced analysis and plotting platform for understanding, plotting, and manipulating the topic model outputs. If things don't seem to make sense, you might need to try different model parameters.
The screenshots below were based on the output generated in version 0.1.2. As of 0.3, each generated output file contains a "Documents" column and a "Words" column. The first contains the total number of documents associated with each topic within each slice, and the second contains the total number of words associated with each topic within each slice. Note that both of these numbers will be decimals because LDA assigns each word in the corpus not to a single topic, but to a distribution over topics.

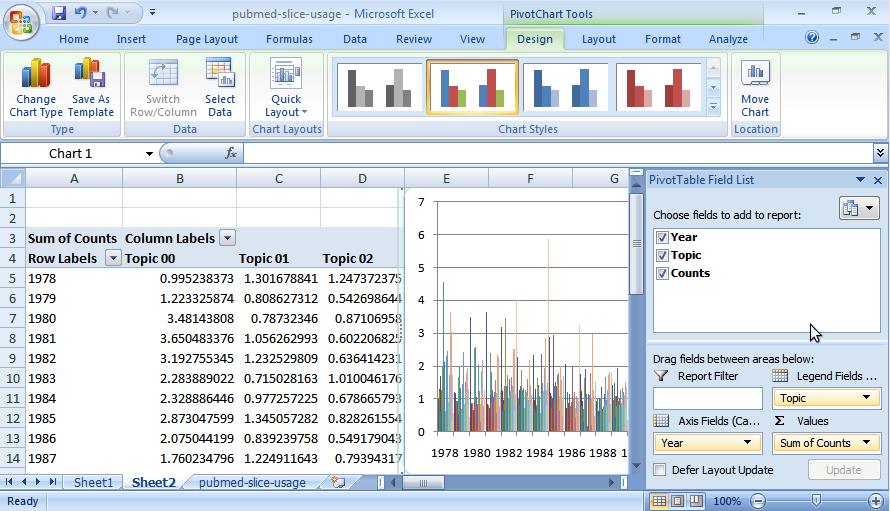

This tutorial describes how to select model parameters such as the number of topics by a (computationally intensive) tuning procedure, which searches for the parameters that minimize the model's perplexity on held-out data.
The code for this example is in example-5-lda-select.scala
More ...The script splits a document into two subsets: one used for training models, the other used for evaluating their perplexity on unseen data. Perplexity is scored on the evaluation documents by first splitting each document in half. The per-document topic distribution is estimated on the first half of the words. The toolbox then computes an average of how surprised it was by the words in the second half of the document, where surprise is measured in the number of equiprobable word choices, on average. The value is written to the console, with lower numbers meaning a surer model.
The perplexity scores are not comparable across corpora because they will be affected by different vocabulary size. However, they can be used to compare models trained on the same data (as in the example script). However, be aware that models with better perplexity scores don't always produce more interpretable topics or topics better suited to a particular task. Perplexity scores can be used as stable measures for picking among alternatives, for lack of a better option. In general, we expect the perplexity to go down as the number of topics increases, but that the successive decreases in perplexity will get smaller and smaller. A good rule of thumb is to pick a number of topics that produces reasonable output (by inspection of summary.txt) and after the perplexity has started to decrease at a
Some non-parametric topic models can automatically select the number of topics as part of the model training procedure itself. However, these models (such as the Hierarchical Dirichlet Process) are not yet implemented in the toolbox. Even in such models, some parameters remain to be tuned, such as the topic smoothing and term smoothing parameters.
[close section]Labeled LDA is a supervised topic model for credit attribution in multi-labeled corpora [pdf, bib]. If one of the columns in your input text file contains labels or tags that apply to the document, you can use Labeled LDA to discover which parts of each document go with each label, and to learn accurate models of the words best associated with each label globally.
The code for this example is in example-6-llda-learn.scala
More ...This example is very similar to the example on training a regular LDA model, except for a few small changes. First, to specify a LabeledLDA dataset, we need to tell the toolbox where the text comes from as well as where the labels come from. In general, Labeled LDA is useful only when each document has more than one label (otherwise, the model is equivalent to Naive Bayes); but in this example, we will use the year column as our label to model. Note that because each document has only a single year, the model will actually converge after a single iteration of training, but the example is structured to work for documents that have multiple labels or tags, space separted, in a single column of the source file.
val source = CSVFile("pubmed-oa-subset.csv") ~> IDColumn(1);
val tokenizer = {
SimpleEnglishTokenizer() ~> // tokenize on space and punctuation
CaseFolder() ~> // lowercase everything
WordsAndNumbersOnlyFilter() ~> // ignore non-words and non-numbers
MinimumLengthFilter(3) // take terms with >=3 characters
}
val text = {
source ~> // read from the source file
Column(4) ~> // select column containing text
TokenizeWith(tokenizer) ~> // tokenize with tokenizer above
TermCounter() ~> // collect counts (needed below)
TermMinimumDocumentCountFilter(4) ~> // filter terms in <4 docs
TermDynamicStopListFilter(30) ~> // filter out 30 most common terms
DocumentMinimumLengthFilter(5) // take only docs with >=5 terms
}
// define fields from the dataset we are going to slice against
val labels = {
source ~> // read from the source file
Column(2) ~> // take column two, the year
TokenizeWith(WhitespaceTokenizer()) ~> // turns label field into an array
TermCounter() ~> // collect label counts
TermMinimumDocumentCountFilter(10) // filter labels in < 10 docs
}
val dataset = LabeledLDADataset(text, labels);
Labeled LDA assumes that each document can use only topics that are named in the label set. Here each document participates in only one label (its year). Years are not particularly interesting labels (versus, say, a field that contained multiple tags describing each paper), but it suffices for this example.
Training a GibbsLabeledLDA or CVB0LabeledLDA model is similar to training an LDA model.
// define the model parameters
val modelParams = LabeledLDAModelParams(dataset);
// Name of the output model folder to generate
val modelPath = file("llda-cvb0-"+dataset.signature+"-"+modelParams.signature);
// Trains the model, writing to the givne output path
TrainCVB0LabeledLDA(modelParams, dataset, output = modelPath, maxIterations = 1000);
// or could use TrainGibbsLabeledLDA(modelParams, dataset, output = modelPath, maxIterations = 1500);
The LabeledLDA model can be used analogously to an LDA model by adapting the previous examples to the labeled setting, as appropriate.
[close section]Partially Labeled Dirchlet Allocation (PLDA) [paper] is a topic model that extends and generalizes both LDA and Labeled LDA. The model is analogous to Labeled LDA except that it allows more than one latent topic per label and a set of background labels. Learning and inference in the model is much like the example above for Labeled LDA, but you must additionally specify the number of topics associated with each label.
Code for this example is in example-7-plda-learn.scala